Uvod v numerične metode in sistemi linearnih enačb#
Uvod v numerične metode#
Kadar želimo simulirati izbrani fizikalni proces, ponavadi postopamo takole:
postavimo matematični model*,
izberemo numerično metodo in njene parametre,
pripravimo program (pomagamo si z vgrajenimi funkcijami),
izvedemo izračun, rezultate analiziramo in vrednotimo.
* Če lahko matematični model rešimo analitično, numerično reševanje ni potrebno.
Matematični model poskušamo rešiti analitično, saj taka rešitev ni obremenjena z napakami. Iz tega razloga se v okviru matematike učimo reševanja sistema enačb, integriranja, odvajanja in podobno. Bistvo numeričnih metod je, da matematične modele rešujemo numerično, torej na podlagi diskretnih vrednosti. Kakor bomo spoznali pozneje, nam numerični pristop v primerjavi z analitičnim omogoča reševanje bistveno obsežnejših in kompleksnejših problemov.
Zaokrožitvena napaka#
V nadaljevanju si bomo pogledali nekatere omejitve in izzive numeričnega pristopa. Prva omejitev je, da so v računalniku realne vrednosti vedno zapisane s končno natančnostjo. V Pythonu se števila pogosto zapišejo v dvojni natančnosti s približno 15 signifikantnimi števkami.
Število z dvojno natančnostjo se v Pythonu imenuje float64 in je zapisano v spomin v binarni obliki v 64 bitih (11 bitov eksponent in 52 bitov mantisa (1 bit za predznak)). Ker je mantisa definirana na podlagi 52 binarnih števk, se lahko pojavi pri njegovem zapisu relativna napaka največ \(\epsilon\approx2.2\cdot 10^{-16}\). Ta napaka se imenuje osnovna zaokrožitvena napaka in se lahko pojavi pri vsakem vmesnem izračunu!
Če je korakov veliko, lahko napaka zelo naraste in zato je pomembno, da je njen vpliv na rezultat čim manjši!
Spodaj je primer podrobnejših informacij za tip podatkov z dvojno natančnostjo (float); pri tem si pomagamo z vgrajenim modulom sys za klic parametrov in funkcij python sistema (dokumentacija):
import sys
sys.float_info.epsilon
1e16+2
#sys.float_info #preverite tudi širši izpis!
1.0000000000000002e+16
Poleg števila z dvojno natančnostjo se uporabljajo drugi tipi podatkov; dober pregled različnih tipov je prikazan v okviru numpy in python dokumentacije.
Tukaj si poglejmo primer tipa int8, kar pomeni celo število zapisano z 8 biti (8 bit = 1 byte). Z njim lahko v dvojiškem sistemu zapišemo cela števila od -128 do +127:
import numpy as np
število = np.int8(1) # poskušite še števila: -128 in nato 127, 128, 129. Kaj se dogaja?
f'Število {število} tipa {type(število)} zapisano v binari obliki:{število:8b}'
"Število 1 tipa <class 'numpy.int8'> zapisano v binari obliki: 1"
Napaka metode#
Poleg zaokrožitvene napake pa se pogosto srečamo tudi z napako metode ali metodično napako, ki jo naredimo takrat, ko natančen analitični postopek reševanja matematičnega modela zamenjamo s približnim numeričnim.
Pomembna lastnost numeričnih algoritmov je stabilnost. To pomeni, da majhna sprememba vhodnih podatkov povzroči majhno spremembo rezultatov. Če se ob majhni spremembi na vhodu rezultati zelo spremenijo, pravimo, da je algoritem nestabilen. V praksi torej uporabljamo stabilne algoritme; bomo pa pozneje spoznali, da je stabilnost lahko pogojena tudi z vhodnimi podatki!
Poznamo pa tudi nestabilnost matematičnega modela/naloge/enačbe; v tem primeru govorimo o slabi pogojenosti.
Med izvajanjem numeričnega izračuna se napake lahko širijo. Posledično je rezultat operacije manj natančen (ima manj zanesljivih števk), kakor pa je zanesljivost podatkov izračuna.
Poglejmo si sedaj splošen pristop k oceni napake. Točno vrednost označimo z \(r\), približek z \(a_1\); velja \(r=a_1+e_1\), kjer je \(e_1\) napaka. Če z numeričnim algoritmom izračunamo bistveno boljši približek \(a_2\), velja \(r=a_2+e_2\).
Ker velja \(a_1+e_1=a_2+e_2\), lahko ob predpostavki \(\left|e_1\right|>>\left|e_2\right|\) in \(\left|e_2\right|\approx 0\) izpeljemo \(a_2-a_1=e_1-e_2\approx e_1\).
\(\left|a_1-a_2\right|\) je torej pesimistična ocena absolutne napake,
\(\left|\frac{a_1-a_2}{a_2}\right|\) pa ocena relativne napake.
Uvod v sisteme linearnih enačb#
Pod zgornjim naslovom razumemo sistem \(m\) linearnih enačb (\(E_i, i=0, 1,\dots,m-1\)) z \(n\) neznankami (\(x_j, j=0,1,\dots,n-1\)):
Koeficienti \(A_{i,j}\) in \(b_i\) so znana števila.
V kolikor je desna stran enaka nič, torej \(b_i=0\), imenujemo sistem homogen, sicer je sistem nehomogen.
Sistem enačb lahko zapišemo tudi v matrični obliki:
kjer sta \(\mathbf{A}\) in \(\mathbf{b}\) znana matrika in vektor, vektor \(\mathbf{x}\) pa ni znan. Matriko \(\mathbf{A}\) imenujemo matrika koeficientov, vektor \(\mathbf{b}\) vektor konstant (tudi: vektor prostih členov ali vektor stolpec desnih strani) in \(\mathbf{x}\) vektor neznank. Če matriki \(\mathbf{A}\) dodamo kot stolpec vektor \(\mathbf{b}\), dobimo t. i. razširjeno matriko in jo označimo \([\mathbf{A}|\mathbf{b}]\).
Opomba glede zapisa:
skalarne spremenljivke pišemo poševno, npr.: \(a, A\),
vektorske spremenljivke pišemo z majhno črko poudarjeno, npr.: \(\mathbf{a}\),
matrične spremenljivke pišemo z veliko črko poudarjeno, npr.: \(\mathbf{A}\).
O rešitvi sistema linearnih enačb#
from IPython.display import YouTubeVideo
YouTubeVideo('7YbyijGUbYw', width=800, height=300)
Če nad sistemom linearnih enačb izvajamo elementarne operacije:
množenje poljubne enačbe s konstanto (ki je različna od nič),
spreminjanje vrstnega reda enačb,
prištevanje ene enačbe (pomnožene s konstanto) drugi enačbi,
rešitve sistema ne spremenimo in dobimo ekvivalentni sistem enačb.
S pomočjo elementarnih operacij nad vrsticami matrike \(\mathbf{A}\) jo lahko preoblikujemo v t. i. vrstično kanonično obliko:
če obstajajo ničelne vrstice, so te na dnu matrike,
prvi neničelni element se nahaja desno od prvih neničelnih elementov predhodnih vrstic,
prvi neničelni element v vrstici imenujemo pivot in je enak 1,
pivot je edini neničelni element v stolpcu.
Rang matrike predstavlja število neničelnih vrstic v vrstični kanonični obliki matrike; število neničelnih vrstic predstavlja število linearno neodvisnih enačb in je enako številu pivotnih elementov. Rang matrike je torej enak številu linearno neodvisnih vrstic matrike. Transponiranje matrike njenega ranga ne spremeni, zato je rang matrike enak tudi številu linearno neodvisnih stolpcev matrike.
Primer preoblikovanja matrike \(\mathbf{A}\):
import numpy as np #uvozimo numpy
A = np.arange(9).reshape((3,3))+1
A
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
Očitno ima neničelni element A[0,0] vrednost 1 in je pivotni element. Prvo vrstico A[0,:] pomnožimo z \(-4\) in produkt prištejemo drugi vrstici A[1,:]-4A[0,:]:
A[1,:] -= A[1,0]*A[0,:]
A
array([[ 1, 2, 3],
[ 0, -3, -6],
[ 7, 8, 9]])
Podobno naredimo za tretjo vrstico:
A[2,:] -= A[2,0]*A[0,:]
A
array([[ 1, 2, 3],
[ 0, -3, -6],
[ 0, -6, -12]])
Drugo vrstico sedaj delimo z A[1,1], da dobimo pivot:
A[1,:] = A[1,:]/A[1,1]
A
array([[ 1, 2, 3],
[ 0, 1, 2],
[ 0, -6, -12]])
Odštejemo drugo vrstico od ostalih, da dobimo v drugem stolpcu ničle povsod, razen v drugi vrstici vrednost 1:
A[0,:] -= A[0,1]*A[1,:] # odštevanje od prve vrstice
A
array([[ 1, 0, -1],
[ 0, 1, 2],
[ 0, -6, -12]])
A[2,:] -= A[2,1]*A[1,:] # odštevanje od zadnje vrstice
A
array([[ 1, 0, -1],
[ 0, 1, 2],
[ 0, 0, 0]])
Imamo dve neničelni vrstici; Matrika A ima dva pivota in predstavlja dve linearno neodvisni enačbi. Rang matrike je 2.
A
array([[ 1, 0, -1],
[ 0, 1, 2],
[ 0, 0, 0]])
Rang matrike pa lahko določimo tudi s pomočjo numpy funkcije numpy.linalg.matrix_rank (dokumentacija):
matrix_rank(M, tol=None)
kjer je M matrika, katere rang iščemo, tol opcijski parameter, ki določa mejo, pod katero se vrednosti v algoritmu smatrajo enake nič.
np.linalg.matrix_rank(A)
np.int64(2)
Če velja \(r=\textbf{rang}(\mathbf{A})=\textbf{rang}([\mathbf{A}|\mathbf{b}])\), potem rešitev obstaja (rečemo tudi, da je sistem konsistenten).
Konsistenten sistem ima:
natanko eno rešitev, ko je število neznank \(n\) enako rangu \(r\) (rešitev je neodvisna) in
neskončno mnogo rešitev, ko je rang \(r\) manjši od števila neznank \(n\) (rešitev je odvisna od \(n-r\) parametrov).
Najprej se bomo omejili na sistem \(m=n\) linearnih enačb z \(n\) neznankami ter velja \(n=r\):
Pod zgornjimi pogoji je matrika koeficientov \(\mathbf{A}\) nesingularna (\(|\mathbf{A}|\neq 0\)) in sistem ima rešitev:
Poglejmo si primer sistema, ko so enačbe linearno odvisne (\(r<n\)):
A = np.array([[1 , 2],
[2, 4]])
b = np.array([1, 2])
Ab = np.column_stack((A,b))
Ab
array([[1, 2, 1],
[2, 4, 2]])
S pomočjo numpy knjižnice poglejmo sedaj rang matrike koeficientov in razširjene matrike ter determinanto z uporabo numpy.linalg.det (dokumentacija):
det(a)
kjer je a matrika (ali seznam matrik), katere determinanto iščemo; funkcija det vrne determinanto (ali seznam determinant).
f'rang(A)={np.linalg.matrix_rank(A)}, rang(Ab)={np.linalg.matrix_rank(Ab)}, \
število neznank: {len(A[:,0])}, det(A)={np.linalg.det(A)}'
'rang(A)=1, rang(Ab)=1, število neznank: 2, det(A)=0.0'
Poglejmo še primer, ko rešitve sploh ni (nekonsistenten sistem):
A = np.array([[1 , 2],
[2, 4]])
b = np.array([1, 1])
Ab = np.column_stack((A,b))
Ab
array([[1, 2, 1],
[2, 4, 1]])
f'rang(A)={np.linalg.matrix_rank(A)}, rang(Ab)={np.linalg.matrix_rank(Ab)}, \
število neznank: {len(A[:,0])}, det(A)={np.linalg.det(A)}'
'rang(A)=1, rang(Ab)=2, število neznank: 2, det(A)=0.0'
Norma in pogojenost sistemov enačb#
Numerična naloga je slabo pogojena, če majhna sprememba podatkov povzroči veliko spremembo rezultata. V primeru majhne spremembe podatkov, ki povzročijo majhno spremembo rezultatov, pa je naloga dobro pogojena.
Sistem enačb je ponavadi dobro pogojen, če so absolutne vrednosti diagonalnih elementov matrike koeficientov velike v primerjavi z absolutnimi vrednostmi izven diagonalnih elementov.
Za sistem linearnih enačb \(\mathbf{A}\,\mathbf{x}=\mathbf{b}\) lahko računamo število pogojenosti (angl. condition number):
Z \(||\textbf{A}||\) je označena norma matrike.
Obstaja več načinov računanja norme; navedimo dve:
Evklidska norma (tudi Frobeniusova):
Norma vsote vrstic ali tudi neskončna norma:
Pogojenost računamo z vgrajeno funkcijo numpy.linalg.cond (dokumentacija):
cond(x, p=None)
ki sprejme dva parametra: matriko x in opcijski tip norme p (privzeti tip je None; v tem primeru se uporabi 2-norma (razmerje največje in najmanjše singularne vrednosti); za Frobeniusovo normo je treba podati p='fro').
Če je število pogojenosti majhno, potem je matrika dobro pogojena in obratno - pri slabi pogojenosti se število pogojenosti zelo poveča.
Žal je izračun pogojenosti matrike numerično relativno zahteven.
Primer slabo pogojene matrike#
Pogledali si bomo slabo pogojen sistem, kjer bomo z malenkostno spremembo na matriki koeficientov povzročili veliko spremembo rešitve.
Matrika koeficientov:
A = np.array([[1 , 1],
[1, 1.00001]])
np.linalg.cond(A)
np.float64(400002.0000028382)
Vektor konstant:
b = np.array([3, -3])
Ab = np.column_stack((A,b))
Ab
array([[ 1. , 1. , 3. ],
[ 1. , 1.00001, -3. ]])
Preverimo rang in determinanto:
f'rang(A)={np.linalg.matrix_rank(A)}, rang(Ab)={np.linalg.matrix_rank(Ab)}, \
število neznank: {len(A[:,0])}, det(A)={np.linalg.det(A)}'
'rang(A)=2, rang(Ab)=2, število neznank: 2, det(A)=1.000000000006551e-05'
Od druge enačbe odštejemo prvo:
Ab[1,:] -= Ab[0,:]
Ab
array([[ 1.e+00, 1.e+00, 3.e+00],
[ 0.e+00, 1.e-05, -6.e+00]])
Določimo x1:
x1 = Ab[1,2]/Ab[1,1]
x1
np.float64(-599999.9999960692)
Preostane še določitev x0:
x0 = (Ab[0,2] - Ab[0,1]*x1)/Ab[0,0]
x0
np.float64(600002.9999960692)
Malenkostno spremenimo matriko koeficientov in ponovimo reševanje:
A = np.array([[1 , 1],
[1, 1.0001]]) # <= tukaj smo spremenili 1.00001 na 1.0001
np.linalg.cond(A)
np.float64(40002.00007491187)
Ponovimo izračun:
Ab = np.column_stack((A,b))
f'rang(A)={np.linalg.matrix_rank(A)}, rang(Ab)={np.linalg.matrix_rank(Ab)}, \
število neznank: {len(A[:,0])}, det(A)={np.linalg.det(A)}'
Ab[1,:] -= Ab[0,:]
x1_ = Ab[1,2]/Ab[1,1]
x0_ = (Ab[0,2] - Ab[0,1]*x1_)/Ab[0,0]
Primerjamo obe rešitvi:
[x0, x1] # prva rešitev
[np.float64(600002.9999960692), np.float64(-599999.9999960692)]
[x0_, x1_] # druga rešitev
[np.float64(60003.00000000661), np.float64(-60000.00000000661)]
Ugotovimo, da je malenkostna sprememba enega koeficienta v matriki koeficientov povzročila veliko spremembo v rezultatu. Majhni spremembi podatkov se ne moremo izogniti, zaradi zapisa podatkov v računalniku.
Numerično reševanje sistemov linearnih enačb#
Pogledali si bomo dva, v principu različna pristopa k reševanju sistemov linearnih enačb:
A) Direktni pristop: nad sistemom enačb izvajamo elementarne operacije, s katerimi predelamo sistem enačb v lažje rešljivega,
B) Iterativni pristop: izberemo začetni približek, nato pa približek iterativno izboljšujemo.
Gaussova eliminacija#
Predpostavimo, da rešujemo sistem \(n\) enačb za \(n\) neznank, ki ima rang \(n\). Tak sistem je enolično rešljiv.
Gaussova eliminacija spada med direktne metode, saj s pomočjo elementarnih vrstičnih operacij sistem enačb prevedemo v zgornje poravnani trikotni sistem (pod glavno diagonalo v razširjeni matriki so vrednosti nič).
Najprej pripravimo razširjeno matriko koeficientov:
Gaussovo eliminacijo si bomo pogledali na zgledu:
A = np.array([[ 8., -6, 3],
[-6, 6,-6],
[ 3, -6, 6]])
b = np.array([-14, 36, 6])
Ab = np.column_stack((A,b))
Ab
array([[ 8., -6., 3., -14.],
[ -6., 6., -6., 36.],
[ 3., -6., 6., 6.]])
Korak 0: prvo vrstico pomnožimo z Ab[1,0]/Ab[0,0]=-6/8 in odštejemo od druge:
Ab[1,:] -= Ab[1,0]/Ab[0,0] * Ab[0,:]
Ab
array([[ 8. , -6. , 3. , -14. ],
[ 0. , 1.5 , -3.75, 25.5 ],
[ 3. , -6. , 6. , 6. ]])
Nato prvo vrstico pomnožimo z Ab[2,0]/Ab[0,0]=3/8 in odštejemo od tretje:
Ab[2,:] -= Ab[2,0]/Ab[0,0] * Ab[0,:]
Ab
array([[ 8. , -6. , 3. , -14. ],
[ 0. , 1.5 , -3.75 , 25.5 ],
[ 0. , -3.75 , 4.875, 11.25 ]])
Korak 1: drugo vrstico pomnožimo z Ab[2,1]/Ab[1,1]=-3.75/1.5 in odštejemo od tretje:
Ab[2,:] -= Ab[2,1]/Ab[1,1] * Ab[1,:]
Ab
array([[ 8. , -6. , 3. , -14. ],
[ 0. , 1.5 , -3.75, 25.5 ],
[ 0. , 0. , -4.5 , 75. ]])
S pomočjo pripravljenega modula moduli/gauss_prikaz.py lahko postopek tudi animiramo:
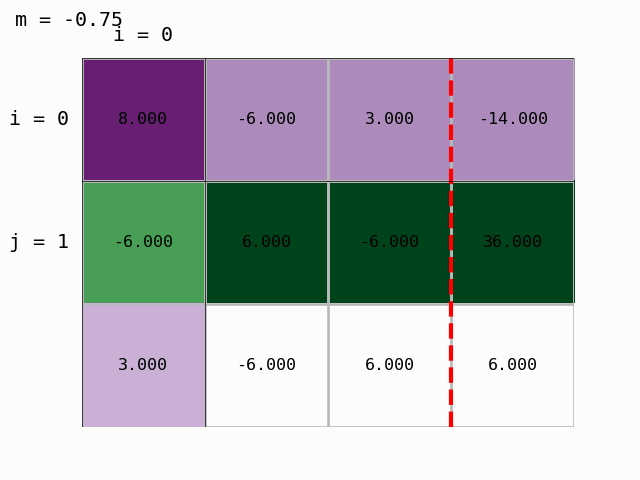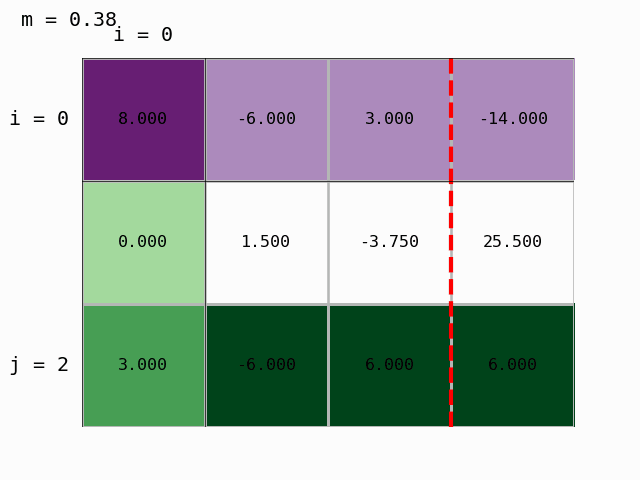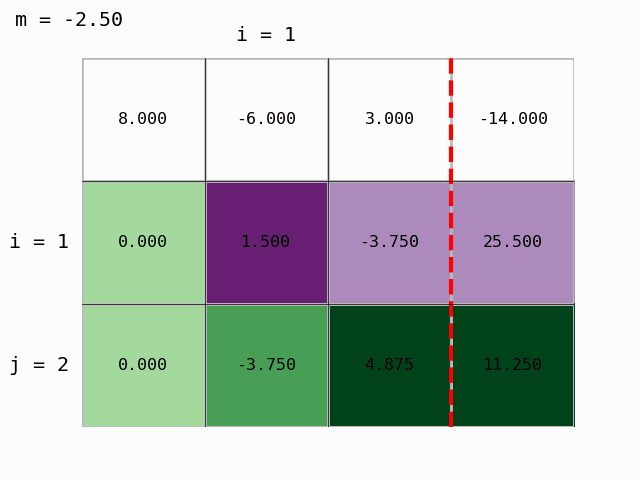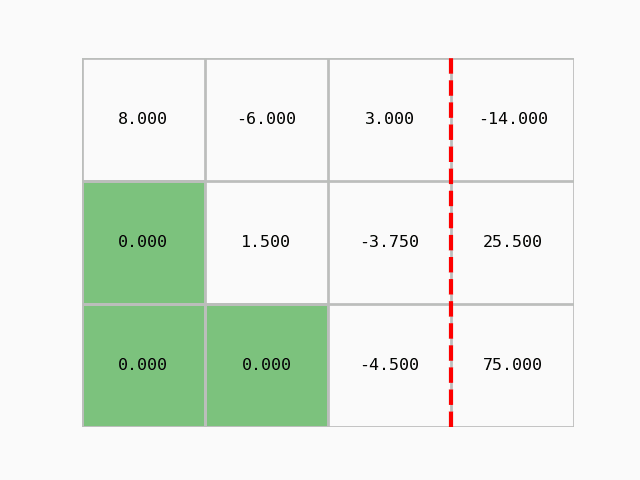
Dobili smo zgornje trikotno matriko in Gaussova eliminacija je končana. Lahko izračunamo rešitev, torej določimo vektor neznank \(x\) z obratnim vstavljanjem.
Iz zadnje vrstice zgornje trikotne matrike izračunamo \(x_2\):
Ab
array([[ 8. , -6. , 3. , -14. ],
[ 0. , 1.5 , -3.75, 25.5 ],
[ 0. , 0. , -4.5 , 75. ]])
x = np.zeros(3) #pripravimo prazen seznam
x[2] = Ab[2,-1]/Ab[2,2]
x
array([ 0. , 0. , -16.66666667])
S pomočjo predzadnje vrstice izračunamo \(x_1\):
Ab
array([[ 8. , -6. , 3. , -14. ],
[ 0. , 1.5 , -3.75, 25.5 ],
[ 0. , 0. , -4.5 , 75. ]])
x[1] = (Ab[1,-1] - Ab[1,2]*x[2]) / Ab[1,1]
x
array([ 0. , -24.66666667, -16.66666667])
S pomočjo prve vrstice nato izračunamo \(x_0\):
Ab
array([[ 8. , -6. , 3. , -14. ],
[ 0. , 1.5 , -3.75, 25.5 ],
[ 0. , 0. , -4.5 , 75. ]])
x[0] = (Ab[0,3] - Ab[0,1:3]@x[1:]) / Ab[0,0]
x
array([-14. , -24.66666667, -16.66666667])
Preverimo rešitev:
A @ x - b
array([-3.55271368e-15, 7.10542736e-15, 7.10542736e-15])
Povzetek Gaussove eliminacije#
V modul orodja.py shranimo funkciji:
def gaussova_eliminacija(A, b, prikazi_korake = False):
Ab = np.column_stack((A, b))
for p, pivot_vrsta in enumerate(Ab[:-1]):
for vrsta in Ab[p+1:]:
if pivot_vrsta[p]:
vrsta[p:] -= pivot_vrsta[p:]*vrsta[p]/pivot_vrsta[p]
else:
raise Exception('Deljenje z 0.')
if prikazi_korake:
print('Korak: {:g}'.format(p))
print(Ab)
return Ab
def gaussova_el_resitev(Ub):
v = len(Ub)
x = np.zeros(v)
for p, pivot_vrsta in enumerate(Ub[::-1]):
x[v-p-1] = (pivot_vrsta[-1] - pivot_vrsta[v-p:-1] @ x[v-p:] ) / (pivot_vrsta[v-p-1])
return x
Algoritem, s katerim iz zgornje trikotnega sistema enačb \(\mathbf{U}\,\mathbf{x}=\mathbf{b}\) izračunamo rešitev, imenujemo obratno vstavljanje (angl. back substitution); \(\mathbf{U}\) je zgornje trikotna matrika.
V kolikor bi reševali sistem \(\mathbf{L}\,\mathbf{x}=\mathbf{b}\) in je \(\mathbf{L}\) spodnje trikotna matrika, bi to metodo imenovali direktno vstavljanje (angl. forward substitution).
Ub = gaussova_eliminacija(A, b, prikazi_korake=False)
Ub
array([[ 8. , -6. , 3. , -14. ],
[ 0. , 1.5 , -3.75, 25.5 ],
[ 0. , 0. , -4.5 , 75. ]])
gaussova_el_resitev(Ub)
array([-14. , -24.66666667, -16.66666667])
Numerična zahtevnost#
Numerično zahtevnost ocenjujemo po številu matematičnih operacij, ki so potrebne za izračun. Za rešitev \(n\) linearnih enačb tako z Gaussovo eliminacijo potrebujemo približno \(n^3/3\) matematičnih operacij. Za določitev neznank \(\mathbf{x}\) potrebujemo še dodatnih približno \(n^2\) operacij.
Pri Gaussovi eliminaciji smo eliminacijo izvedli samo za člene pod diagonalo; če bi z eliminacijo nadaljevali in jo izvedli tudi za člene nad diagonalo, bi izvedli t. i. Gauss-Jordanovo eliminacijo, za katero pa potrebujemo dodatnih približno \(n^3/3\) operacij* (kar se šteje kot glavna slabost te metode).
* Nekaj komentarjev na temo števila numeričnih operacij najdete tukaj: pinm.ladisk.si.
Uporaba knjižnjice numpy#
Reševanje sistema linearnih enačb z numpy.linalg.solve (dokumentacija):
solve(a, b)
kjer je a matrika koeficientov (ali seznam matrik) in je b vektor konstant (ali seznam vektorjev). Funkcija vrne vektor (ali seznam vektorjev) rešitev.
np.linalg.solve(A, b)
array([-14. , -24.66666667, -16.66666667])
Dodatno#
Primer simbolnega reševanja sistema linearnih enačb v okviru sympy#
import sympy as sym
sym.init_printing()
A11, A12, A21, A22 = sym.symbols('A11, A12, A21, A22')
x1, x2 = sym.symbols('x1, x2')
b1, b2 = sym.symbols('b1, b2')
A = sym.Matrix([[A11, A12],
[A21, A22]])
x = sym.Matrix([[x1],
[x2]])
b = sym.Matrix([[b1],
[b2]])
eq = sym.Eq(A*x,b)
eq
#%%timeit
resitev = sym.solve(eq,[x1, x2])
resitev
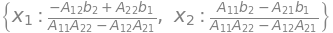
A.det()

Vprašanja za vaje#
Sistemi linearnih algebrajskih enačb#
Vprašanje 1: Spodaj zapisan sistem linearnih enačb definirajte in rešite z uporabo orodij paketa numpy. S pomočjo matričnega množenja preverite pravilnost rešiteve.
Vprašanje 2: Enačbe ravnotežja sil in momentov za nosilec na sliki zapišemo:

Določite reakcije v podporah \([A_x, A_y, B]\), tako da definirate sistem enačb v okolju numpy in ga rešite z obstoječimi orodji.
Podatki:
\(L = 1\) m
\(a = 0.3\) m
\(F = 105\) N
\(\varphi = \pi /3 \) rad
Vprašanje 3: Obravnavate nosilec, zelo podoben tistemu na zgornji sliki. Poznate kot \(\varphi\) in vrednost \(a\), pomerili ste reakciji v podporah v navpični smeri, a ne poznate dolžine nosilca, amplitude sile \(F\), ter vrednosti \(A_x\).
Ravnotežne enačbe ostajajo enake:
Izračunajte vrednosti \([A_x, F, L]\).
Podatki:
\(a = 0.6\) m
\(A_y = 72\) N
\(B = 31\) N
\(\varphi = \pi /4 \) rad
Enoličnost rešitve#
Vprašanje 4: Pripravi funkcijo, ki preveri če je sistem enačb enolično rešljiv. Funkcija naj kot argument sprejme matriko koeficientov \(\mathbf{A}\) in vektor konstatnt \(\bold{b}\). Če je sistem rešljiv naj vrne True, drugače naj sproži ValueError.
Preverite rešitev naslednjih sistemov enačb in komentirajte.
# Podatki
A_1 = np.array([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 10.]])
b_1 = np.array([6., 15., 25.])
A_2 = np.array([[1., 2., 3.],
[2., 4., 6.],
[3., 6., 9.]])
b_2 = np.array([1., 2., 4.])
A_3 = np.array([[1., 2., 3.],
[2., 4., 6.],
[3., 6., 9.]])
b_3 = np.array([6., 12., 18.])
Gaussova eliminacija#

Vprašanje 5: Pripravite funkcijo gauss_eliminacija, ki:
kot argumenta sprejme matriko \(\mathbf{A}\) in vektor \(\mathbf{b}\),
pripravi razširjeno matriko koeficientov \(\mathbf{[A|b]}\)
za vsako pivotno vrstico
i, \(0 \leq i \leq n-1\), izračuna koeficient \(\lambda\) za vse vrstice pod pivotno (\(i+1 \leq j \leq n\)) (\(n\) je število vrstic \(\mathbf{A}\)).
če je koeficient \(a_{ii}\) različen od 0, opravi zamenjavo:
Vprašanje 6: Pripravte funkijo gauss_resitev, ki na podlagi rezutata funkcije gauss_eliminacija izračuna vrednosti elementov vektorja neznank \(\mathbf{x}\) z uporabo obratnega vstavljanja.
Namig: Sistem z zgornje trikotno razširjeno matriko koeficientov rešujemo „od spodaj navzgor“. Vrstni red vrstic matrike lahko obrnete z A[::-1].
Pogojenost sistemov linearnih enačb#
Vprašanje 7: Z uporabo orodij paketa numpy rešite spodnji sistem enačb. Nato element A[2,1]povečajte za \(0.1\)% in nov sistem rešite še enkrat. Komentirajte rezultat, pomagajte si z vrednostjo determinante, norme in pogojenosti matrike \(\mathbf{A}\).
# Podatek, ne briši!
A = np.array([[1.1, 22, -35],
[-7.0, -2.4, 3.5],
[0.3, 6.6, -10.5]])
b = np.array([3, -0.5, 1.5])
Vprašanje 8: Z uporabo orodij paketa numpy pripravite lastne funkcije za Evklidsko ali neskončno normo ter merilo pogojenosti matrike. Izračunajte pogojenost matrike koeficientov iz zgornje naloge.
Evklidska (Frobeniusova) norma (koren vsote kvadratov vseh elementov):
\[||\textbf{A}||_e=\sqrt{\sum_{i=1}^n\sum_{j=1}^nA_{ij}^2}\]Neskončna norma (maksimum vsote vrstic):
Število pogojenosti: