Sistemi linearnih enačb (2)
Razcep LU¶
Za rešitev sistema linearnih enačb zahteva Gaussov eliminacijski postopek najmanjše število računskih operacij.
V primeru, ko se matrika koeficientov $\mathbf{A}$ ne spreminja in se spreminja zgolj vektor konstant $\mathbf{b}$, se je mogoče izogniti ponovni Gaussovi eliminaciji matrike koeficientov. Z razcepom matrike $\mathbf{A}$ lahko pridemo do rešitve z manj računskimi operacijami. V ta namen si bomo pogledali razcep LU!
Poljubno matriko lahko zapišemo kot produkt dveh matrik: $$\mathbf{A}=\mathbf{B}\,\mathbf{C}.$$ Pri tem je možnosti za zapis matrik $\mathbf{B}$ in $\mathbf{C}$ neskončno veliko.
Pri razcepu LU zahtevamo, da je matrika $\mathbf{B}$ spodnje trikotna in matrika $\mathbf{C}$ zgornje trikotna:
$$\mathbf{A}=\mathbf{L}\,\mathbf{U}.$$Vsaka od matrik $\mathbf{L}$ in $\mathbf{U}$ ima $(n+1)\,n/2$ neničelnih elementov; skupaj torej $n^2+n$ neznank. Znana matrika $\mathbf{A}$ definira $n^2$ vrednosti. Za enolično določitev matrik $\mathbf{L}$ in $\mathbf{U}$ torej manjka $n$ enačb. Tukaj bomo uporabili razcep LU, ki dodatne enačbe pridobi s pogojem $L_{ii}=1$, $i=0, 1,\dots,n-1$.
Sistem linearnih enačb: $$\mathbf{A}\mathbf{x}=\mathbf{b}$$ torej zapišemo z razcepom matrike $\mathbf{A}$: $$\mathbf{L}\,\underbrace{\mathbf{U}\,\mathbf{x}}_{\mathbf{y}}=\mathbf{b}.$$
Do rešitve sistema $\mathbf{A}\mathbf{x}=\mathbf{b}$ sedaj pridemo tako, da rešimo dva trikotna sistema enačb.
Najprej izračunamo vektor $\mathbf{y}$: $$\mathbf{L}\,\mathbf{y}=\mathbf{b}.\qquad \textrm{(direktno vstavljanje)}$$ Ko je $\mathbf{y}$ izračunan, lahko iz: $$\mathbf{U}\,\mathbf{x}=\mathbf{y}\qquad \textrm{(obratno vstavljanje)}$$ določimo $\mathbf{x}$.
Razcep LU matrike koeficientov $\mathbf{A}$¶
V nadaljevanju bomo pokazali, da Gaussova eliminacija dejanjsko predstavlja razcep LU matrike koeficientov $\mathbf{A}$. Pri tem si bomo pomagali s simbolnim izračunom, zato uvozimo paket sympy:
import sympy as sym # uvozimo sympy
sym.init_printing() # za lep prikaz izrazov
Prikaz začnimo na primeru simbolno zapisanih matrik $\mathbf{L}$ in $\mathbf{U}$ dimenzije $3\times 3$:
L21, L31, L32 = sym.symbols('L21, L31, L32')
U11, U12, U13, U22, U23, U33 = sym.symbols('U11, U12, U13, U22, U23, U33')
L = sym.Matrix([[ 1, 0, 0],
[L21, 1, 0],
[L31, L32, 1]])
U = sym.Matrix([[U11, U12, U13],
[ 0, U22, U23],
[ 0, 0, U33]])
Matrika koeficientov $\mathbf{A}$ zapisana z elementi matrik $\mathbf{L}$ in $\mathbf{U}$ torej je:
A = L*U
A
Izvedimo sedaj Gaussovo eliminacijo nad matriko koeficientov $\mathbf{A}$.
S pomočjo prve vrstice izvedemo Gaussovo eliminacijo v prvem stolpcu:
A[1,:] -= L21 * A[0,:]
A[2,:] -= L31 * A[0,:]
A
Nadaljujemo v drugem stolpcu:
A[2,:] -= L32 * A[1,:]
A
Iz zgornje eliminacije ugotovimo:
- matrika $\mathbf{U}$ je enaka matriki, ki jo dobimo, če izvedemo Gaussovo eliminacijo nad matriko koeficientov $\mathbf{A}$.
- izven diagonalni členi $\mathbf{L}$ so faktorji, ki smo jih uporabili pri Gaussovi eliminaciji.
Numerična implementacija razcepa LU¶
Numerično implementacijo si bomo pogledali na sistemu, ki je definiran kot:
import numpy as np
A = np.array([[8, -6, 3],
[-6, 6, -6],
[3, -6, 6]], dtype=float)
b = np.array([-14, 36, 6], dtype=float)
Izvedimo Gaussovo eliminacijo in koeficiente, s katerim množimo pivotno vrsto m, shranimo v matriko L na mesto z indeksi, kot jih ima v matriki $\mathbf{A}$ eliminirani element.
(v, s) = A.shape # v=število vrstic, s=število stolpcev
U = A.copy() # pripravimo matriko U kot kopijo A
L = np.zeros_like(A) # pripravimo matriko L dimenzije enake A (vrednosti 0)
# eliminacija
for p, pivot_vrsta in enumerate(U[:-1]):
for i, vrsta in enumerate(U[p+1:]):
if pivot_vrsta[p]:
m = vrsta[p]/pivot_vrsta[p]
vrsta[p:] = vrsta[p:]-pivot_vrsta[p:]*m
L[p+1+i, p] = m
print('Korak: {:g}'.format(p))
print(U)
L
Dopolnimo diagonalo $\mathbf{L}$:
for i in range(v):
L[i, i] = 1.
L
Sedaj rešimo spodnje trikotni sistem enačb $\mathbf{L}\,\mathbf{y}=\mathbf{b}$:
# direktno vstavljanje
y = np.zeros_like(b)
for i, b_ in enumerate(b):
y[i] = (b_ - np.dot(L[i, :i], y[:i]))
y
Nadaljujemo z reševanjem zgornje trikotnega sistema $\mathbf{U}\,\mathbf{x}=\mathbf{y}$:
U
y
# obratno vstavljanje
x = np.zeros_like(b)
for i in range(v-1, -1,-1):
x[i] = (y[i] - np.dot(U[i, i+1:], x[i+1:])) / U[i, i]
x
Kakor smo navedli zgoraj, ob spremembi vektorja konstant $\mathbf{b}$ ponovna Gaussova eliminacija ni potrebna. Izvesti je treba samo direktno in nato obratno vstavljanje. Poglejmo primer:
b = np.array([-1., 6., 7.])
y = np.zeros_like(b)
for i, b_ in enumerate(b):#direktno vstavljanje
y[i] = (b_ - np.dot(L[i, :i], y[:i]))
x = np.zeros_like(b)
for i in range(v-1, -1,-1):# obratno vstavljanje
x[i] = (y[i] - np.dot(U[i, i+1:], x[i+1:])) / U[i, i]
x
A.dot(x)
Pivotiranje¶
Poglejmo si spodnji sistem enačb:
A = np.array([[0, -6, 6],
[-6, 6, -6],
[8, -6, 3]], dtype=float) # poskusite tukaj izpustiti dtype=float in preveriet rezultat
b = np.array([6, 36, -14], dtype=float)
Če bi izvedli Gaussovo eliminacijo v prvem stolpcu matrike $\mathbf{A}$:
A[1,:] - A[1,0]/A[0,0] * A[0,:]
Opazimo, da imamo težavo z deljenjem z 0 v prvi vrstici. Elementarne operacije, ki jih nad sistemom lahko izvajamo, dovoljujejo zamenjavo poljubnih vrstic. Sistem lahko preuredimo tako, da pivotni element ni enak 0. Vseeno se lahko zgodi, da ima pivotni element, s katerim delimo, zelo majhno vrednost $\varepsilon$. Ker bi to povečevalo zaokrožitveno napako, izmed vseh vrstic za pivotno vrstico izberemo tisto, katere pivot ima največjo absolutno vrednost.
Če med Gaussovo eliminacijo zamenjamo vrstice tako, da je pivotni element največji, to imenujemo pivotiranje vrstic ali tudi delno pivotiranje. Tako dosežemo, da je Gaussova eliminacija numerično stabilna.
Pokazati je mogoče, da pri reševanju sistema enačb $\mathbf{A}\,\mathbf{x}=\mathbf{b}$, pri katerem je matrika $\mathbf{A}$ diagonalno dominantna, pivotiranje po vrsticah ni potrebno. Reševanje je brez pivotiranja numerično stabilno.
Pravokotna matrika $\mathbf{A}$ dimenzije $n$ je diagonalno dominantna, če je absolutna vrednost diagonalnega elementa vsake vrstice večja od vsote absolutnih vrednosti ostalih elementov v vrstici: $$\left|A_{ii}\right|> \sum_{j=1, j\ne i}^n \left|A_{ij}\right|$$
Gaussova eliminacija z delnim pivotiranjem¶
Pogledali si bomo Gaussovo eliminacijo z delnim pivotiranjem. Brez delnega pivotiranja v $i$-tem koraku eliminacije izberemo vrstico $i$ za pivotiranje. Pri delnem pivotiranju pa najprej preverimo, ali je $i$-ti diagonalni element po absolutni vrednosti največji element v stolpcu $i$ na ali pod diagonalo; če ni, zamenjamo vrstico $i$ s tisto vrstico pod njo, v kateri je v stolpcu $i$ po absolutni vrednosti največji element. Z delnim pivotiranjem zmanjšamo vpliv zaokrožitvene napake na rezultat.
V koliko bi izvedli polno pivotiranje, bi poleg zamenjave vrstic uporabili tudi zamenjavo vrstnega reda spremenljivk (zamenjava stolpcev). Polno pivotiranje izboljša stabilnost, se pa redko uporablja in ga tukaj ne bomo obravnavali.
Algoritem za Gaussovo eliminacijo z delnim pivotiranjem torej je:
def gaussova_eliminacija_pivotiranje(A, b, prikazi_korake=False):
""" Vrne Gaussovo eliminacijo razširjene matrike koeficientov,
uporabi delno pivotiranje.
:param A: matrika koeficientov
:param b: vektor konstant
:param prikazi_korake: ali izpišem posamezne korake
:return Ab: trapezna razširjena matrika koeficientov
"""
Ab = np.column_stack((A, b))
for p in range(len(Ab)-1):
p_max = np.argmax(np.abs(Ab[p:,p]))+p
if p != p_max:
Ab[[p], :], Ab[[p_max], :] = Ab[[p_max], :], Ab[[p], :]
pivot_vrsta = Ab[p, :]
for vrsta in Ab[p + 1:]:
if pivot_vrsta[p]:
vrsta[p:] -= pivot_vrsta[p:] * vrsta[p] / pivot_vrsta[p]
if prikazi_korake:
print('Korak: {:g}'.format(p))
print('Pivot vrsta:', pivot_vrsta)
print(Ab)
return Ab
A
Ab = gaussova_eliminacija_pivotiranje(A, b, prikazi_korake=True)
Razcep LU z delnim pivotiranjem¶
Podobno kakor pri Gaussovi eliminaciji lahko tudi razcep LU razširimo z delnim pivotiranjem. Reševanje tako postane numerično stabilno. Pri tem moramo shraniti informacijo o zamenjavi vrstic, ki jo potem posredujemo v funkcijo za rešitev ustreznih trikotnih sistemov.
def LU_razcep_pivotiranje(A, prikazi_korake=False):
""" Vrne razcep LU matriko in vektor zamenjanih vrstic pivotiranje,
uporabi delno pivotiranje.
:param A: matrika koeficientov
:param prikazi_korake: izpišem posamezne korake
:return LU: LU matrika
:return pivotiranje: vektor zamenjave vrstic (pomembno pri iskanju rešitve)
"""
LU = A.copy()
pivotiranje = np.arange(len(A))
for p in range(len(LU)-1):
p_max = np.argmax(np.abs(LU[p:,p]))+p
if p != p_max:
LU[[p], :], LU[[p_max], :] = LU[[p_max], :], LU[[p], :]
pivotiranje[p], pivotiranje[p_max] = pivotiranje[p_max], pivotiranje[p]
pivot_vrsta = LU[p, :]
for vrsta in LU[p + 1:]:
if pivot_vrsta[p]:
m = vrsta[p] / pivot_vrsta[p]
vrsta[p:] -= pivot_vrsta[p:] * m
vrsta[p] = m
else:
raise Exception('Deljenje z 0.')
if prikazi_korake:
print('Korak: {:g}'.format(p))
print('Pivot vrsta:', pivot_vrsta)
print(LU)
return LU, pivotiranje
Poglejmo si primer:
A = np.array([[0, -6, 6],
[-6, 6, -6],
[8, -6, 3]], dtype=float)
b = np.array([-14, 36, 6], dtype=float)
lu, piv = LU_razcep_pivotiranje(A, prikazi_korake=True)
V zgornjem primeru smo uporabili kompaketen način zapisa trikotnih matrik $\mathbf{L}$ in $\mathbf{U}$; vsaka je namreč definirana s 6 elementi, pri matriki $\mathbf{L}$ pa vemo, da so diagonalni elementi enaki 1. Matrika lu tako vsebuje $3\times3=9$ elementov:
lu
Na diagonali in nad diagonalo so vrednosti zgornje trikotne matrike $\mathbf{U}$, pod diagonalo pa so poddiagonalni elementi matrike $\mathbf{L}$. Pri izračunu rešitve bomo upoštevali, da so diagonalne vrednosti $\mathbf{L}$ enake 1.
Numerični seznam piv nam pove, kako so bile zamenjane vrstice, kar je treba upoštevati pri izračunu rešitve:
piv
Določimo sedaj še rešitev (koda za računanje rešitve je v modulu orodja.py)
from moduli import orodja
r = orodja.LU_resitev_pivotiranje(lu, b, piv)
r
Preverjanje rešitve:
A@r
Modul SciPy¶
Modul SciPy temelji na numpy modulu in vsebuje veliko različnih visokonivojskih programov/modulov/funkcij. Teoretično ozadje modulov so seveda različni numerični algoritmi; nekatere spoznamo tudi v okviru tega učbenika. Dober vir teh numeričnih algoritmov v povezavi s SciPy predstavlja dokumentacija. Za odličen uvod v SciPy si lahko ogledate YouTube posnetek: SciPy Tutorial (2021): For Physicists, Engineers, and Mathematicians: For Physicists, Engineers, and Mathematicians
Kratek pregled hierarhije modula:
- Linearna algebra (scipy.linalg)
- Integracija (scipy.integrate)
- Optimizacija (scipy.optimize)
- Interpolacija (scipy.interpolate)
- Fourierjeva transformacija (scipy.fftpack)
- Problem lastnih vrednosti (redke matrike) (scipy.sparse)
- Statistika (scipy.stats)
- Procesiranje signalov (scipy.signal)
- Posebne funkcije (scipy.special)
- Večdimenzijsko procesiranje slik (scipy.ndimage)
- Delo z datotekami (scipy.io)
V sledečih predavanjih si bomo nekatere podmodule podrobneje pogledali.
Poglejmo si, kako je znotraj SciPy implementiran razcep LU:
from scipy.linalg import lu_factor, lu_solve
Funkcija scipy.linalg.lu_factor (dokumentacija):
lu_factor(a, overwrite_a=False, check_finite=True)
zahteva vnos matrike koeficientov (ali seznama matrik koeficientov) a, overwrite_a v primeru True z rezultatom razcepa prepiše vrednost a (to je lahko pomembno, da se prihrani spomin in poveča hitrost). Funkcija lu_factor vrne terko (lu, piv):
lu- $\mathbf{L}$ \ $\mathbf{U}$ matrika (matrika, ki je enake dimenzije kota, vendar pod diagonalo vsebuje elemente $\mathbf{L}$, preostali elementi pa definirajo $\mathbf{U}$; diagonalni elementi $\mathbf{L}$ imajo vrednosti 1.piv- pivotni indeksi, predstavljajo permutacijsko matrikoP: vrstaimatrikeaje bila zamenjana z vrstopiv[i](v vsakem koraku se upošteva predhodno stanje, malo drugačna logika kot v naši funkcijiLU_razcep_pivotiranje).
lu_factor uporabljamo v paru s funkcijo scipy.linalg.lu_solve (dokumentacija), ki nam poda rešitev sistema:
lu_solve(lu_and_piv, b, trans=0, overwrite_b=False, check_finite=True)
lu_and_piv je terka rezultata (lu, piv) iz lu_factor, b je vektor (ali seznam vektorjev) konstant. Ostali parametri so opcijski.
Poglejmo si uporabo:
A = np.array([[0, -6, 6],
[-6, 6, -6],
[8, -6, 3]], dtype=float)
b = np.array([-14, 36, 6], dtype=float)
lu, piv = lu_factor(A)
lu
piv
Pridobimo rešitev:
r = lu_solve((lu, piv), b)
r
Preverimo ustreznost rešitve:
A@r
Računanje inverzne matrike¶
Inverzno matriko h kvadratni matriki $\textbf{A}$ reda $n\times n$ označimo z $\textbf{A}^{-1}$. Je matrika reda $n\times n$, takšna, da velja $$\mathbf{A}\,\mathbf{A}^{-1} = \mathbf{A}^{-1}\,\mathbf{A} = \mathbf{I},$$ kjer je $\mathbf{I}$ enotska matrika.
Najbolj učinkovit način za izračun inverzne matrike od matrike $\mathbf{A}$ je rešitev matrične enačbe: $$\mathbf{A}\,\mathbf{X}=\mathbf{I}.$$ Matrika $\mathbf{X}$ je inverzna matriki $\mathbf{A}$: $\mathbf{A}^{-1}=\mathbf{X}$.
Izračun inverzne matrike je torej enak reševanju $n$ sistemov $n$ linarnih enačb: $$\mathbf{A}\,\mathbf{x}_i=\mathbf{b}_i,\qquad i=0,1,2,\dots,n-1,$$ kjer je $\mathbf{b}_i$ $i$-ti stolpec matrike $\mathbf{B}=\mathbf{I}$.
Numerična zahtevnost: izvedemo razcep LU nad matriko $\mathbf{A}$ (računski obseg reda $n^3$) in nato poiščemo rešitev za vsak $\mathbf{x}_i$ ($2\,n^2$ računskih operacij za vsak $i$). Skupni računski obseg je torej še vedno reda $n^3$. (Če bi $n$ krat izvajali Gaussovo eliminacijo, bi bil obseg reda $n^4$.)
lu_piv = lu_factor(A)
lu_piv
Tukaj se sedaj pokaže smisel razcepa LU; razcep namreč izračunamo samo enkrat in potem za vsak vektor konstant poiščemo rešitev tako, da rešimo dva trikotna sistema. Če bi sisteme reševali po Gaussovi metodi, bi rabili $(n^3+n^2)\,n$ računskih operacij.
Izračunajmo inverzno matriko od matrike $\textbf{A}$. Najprej z uporabo np.identity() pripravimo enotsko matriko:
np.identity(len(A))
Nato rešimo sistem enačb za vsak stolpec enotske matrike:
A_inv = np.zeros_like(A) #zeros_like vrne matriko oblike in tipa matrike A z vrednostmi 0
for b, a_inv in zip(np.identity(len(A)), A_inv):
a_inv[:] = lu_solve(lu_piv, b)
A_inv = A_inv.T
Rešitev torej je:
A_inv
Preverimo rešitev:
A@A_inv
Rešitev z uporabo Numpy:
#%%timeit
np.linalg.inv(A)
Z ustrezno uporabo funkcij iz modula SciPy lahko do rešitve pridemo še hitreje. V funkcijo lu_solve lahko vstavimo vektor $\mathbf{b}$ ali matriko $\mathbf{B}$, katere posamezni stolpec $i$ predstavlja nov vektor konstant $\mathbf{b}_i$.
#%%timeit
lu_solve(lu_piv, np.identity(len(A)))
Reševanje predoločenih sistemov¶
from IPython.display import YouTubeVideo
YouTubeVideo('N6upu99LbfQ', width=800, height=300)
Kadar rešujemo sistem $m$ linearnih enačbami z $n$ neznankami ter velja $m>n$ in je rang $n+1$, imamo predoločeni sistem.
Predoločeni (tudi nekonsistenten sistem): $$\mathbf{A}\,\mathbf{x}=\mathbf{b},$$ nima rešitve. Lahko pa poiščemo najboljši približek rešitve z metodo najmanjših kvadratov .
Vsota kvadratov preostankov je definirana s skalarnim produktom: $$\left\lVert r\right\rVert ^2=(\mathbf{A}\,\mathbf{x}-\mathbf{b})^T\,(\mathbf{A}\,\mathbf{x}-\mathbf{b})$$ kar preoblikujemo v: $$\left\lVert r\right\rVert^2=\mathbf{x}^T\mathbf{A}^T\mathbf{A}\mathbf{x}-2\mathbf{b}^T\mathbf{A}\mathbf{x}+\mathbf{b}^T\mathbf{b},$$ kjer smo upoštevali, da zaradi skalarne vrednosti velja: $\mathbf{b}^T\mathbf{A}\mathbf{x}=(\mathbf{b}^T(\mathbf{A}\mathbf{x}))^T=(\mathbf{A}\mathbf{x})^T\mathbf{b}$.
Rešitev enačbe, gradient vsote kvadratov, določa njen minimum: $$\nabla_x\,\left\lVert r\right\rVert^2=2\mathbf{A}^T\mathbf{A}\,\mathbf{x}-2\mathbf{A}^T\,\mathbf{b}=0$$ Tako iz normalne enačbe: $$\mathbf{A}^T\mathbf{A}\,\mathbf{x}=\mathbf{A}^T\,\mathbf{b}$$ določimo najboljši približek rešitve: $$\mathbf{x}=\left(\mathbf{A}^T\mathbf{A}\right)^{-1}\mathbf{A}^T\,\mathbf{b}.$$
Z vpeljavo psevdo inverzne matrike: $$\mathbf{A}^+=\left(\mathbf{A}^T\mathbf{A}\right)^{-1}\mathbf{A}^T$$ k matriki $\mathbf{A}$ je rešitev predoločenega sistema zapisana: $$\mathbf{x}=\mathbf{A}^+\,\mathbf{b}.$$
Zgoraj predstavljen postopek je relativo enostaven, je pa numerično zahteven in lahko v nekaterih primerih slabo pogojen; priporočeno je da v praksi psevdo inverzno matriko izračunamo z uporabo funkcij:
numpy.linalg.pinviz modulanumpy(dokumentacija),- Funkcij
pinv,pinv2alipinvhiz modulascipy.linalg(izbira je odvisna od obravnavanega problema; glejte dokumentacijo),
ki temeljijo na boljših numerični metodah.
Primer sistema z enolično rešitvijo:
# število enačb enako številu neznank
A = np.array([[1., 2],
[2, 3]])
b = np.array([5., 8])
np.linalg.solve(A, b)
Naredimo sedaj predoločeni sistem (funkcija numpy.vstack (dokumentacija) sestavi sezname po stolpcih, numpy.random.seed (dokumentacija) ponastavi generator naključnih števil na vrednost semena seed, numpy.random.normal (dokumentacija) pa generira normalno porazdeljeni seznam dolžine size in standardne deviacije scale):
vA = np.vstack([A,A,A])
np.random.seed(seed=0)
vA += np.random.normal(scale=0.01, size=vA.shape) # pokvarimo rešitev -> sistem je predoločen
vA # matrika koeficientov
vb = np.hstack([b,b,b])
vb += np.random.normal(scale=0.01, size=vb.shape)
vb # vektor konstant
Rešimo sedaj predoločen sistem:
Ap = np.linalg.pinv(vA)
Ap.dot(vb)
Vidimo, da predoločeni sistem z naključnimi vrednostmi (simulacija šuma pri meritvi) poda podoben rezultat kakor rešitev brez šuma. V kolikor bi nivo šuma povečevali, bi se odstopanje od enolične rešitve povečevalo.
Psevdo inverzno matriko lahko določimo tudi sami in preverimo razliko z vgrajeno funkcijo:
#%%timeit # preverite hitrost!
Ap2 = np.linalg.inv(vA.T@vA) @ vA.T
Ap2 - Ap
Iterativne metode¶
Pogosto se srečamo z velikimi sistemi linearnih enačb, katerih matrika koeficientov ima malo od nič različnih elementov (take matrike imenujemo redke ali tudi razpršene, angl. sparse).
Pri reševanju takih sistemov linearnih enačb se zelo dobro izkažejo iterativne metode; prednosti v primerjavi z direktnimi metodami so:
- računske operacije se izvajajo samo nad neničelnimi elementi (kljub iterativnemu reševanju jih je lahko manj)
- zahtevani spominski prostor je lahko neprimerno manjši.
Gauss-Seidlova metoda¶
V nadaljevanju si bomo pogledali idejo Gauss-Seidelove iterativne metode. Najprej sistem enačb $\mathbf{A}\,\mathbf{x}=\mathbf{b}$ zapišemo kot: $$\sum_{j=0}^{n-1} A_{ij}x_j=b_i\qquad{}i=0,1,\dots,n-1.$$
Predpostavim, da smo v $k-1$ koraku iterativne metode in so znani približki $x_{j}^{(k-1)}$ ($j=0,1,\dots, n-1$). Iz zgornje vsote izpostavimo člen $i$: $$A_{ii}\,x_{i}^{(k-1)} +\sum_{j=0, j\ne i}^{n-1} A_{ij}x_{j}^{(k-1)}=b_i\qquad{}i=0,1,\dots,n-1,$$
Ker približki $x_{j}^{(k-1)}$ ne izpolnjujejo natančno linearnega problema, lahko iz zgornje enačbe določimo nov približek $x_{i}^{(k)}$: $$x_{i}^{(k)} =\frac{1}{A_{ii}}\left(b_i-\sum_{j=0}^{i-1} A_{ij}x_{j}^{(k)}-\sum_{j=i+1}^{n-1} A_{ij}x_{j}^{(k-1)}\right)$$
Vsoto smo razdelili na dva dela in za izračun $i$-tega člena upoštevali v $k$-ti iteraciji že določene člene z indeksom manjšim od $i$.
Iterativni pristop prekinemo, ko dosežemo želeno natančnost rešitve $\epsilon$:
$$||x_{i}^{(k)}-x_{i}^{(k-1)}||<\epsilon$$Zgled¶
A = np.array([[8, -1, 1],
[-1, 6, -1],
[0, -1, 6]], dtype=float)
b = np.array([-14, 36, 6], dtype=float)
Začetni približek:
x = np.zeros(len(A))
x
Pripravimo matriko $\mathbf{A}$ brez diagonalnih elementov (Zakaj? Poskusite odgovoriti spodaj, ko bomo izvedli iteracije.)
K = A.copy() #naredimo kopijo, da ne povozimo podatkov
np.fill_diagonal(K, np.zeros(3)) #spremenimo samo diagonalne elemente
K
Izvedemo iteracije:
$$x_{i}^{(k)} =\frac{1}{A_{ii}}\left(b_i-\sum_{j=0}^{i-1} A_{ij}x_{j}^{(k)}-\sum_{j=i+1}^{n-1} A_{ij}x_{j}^{(k-1)}\right)$$
(Ker bomo vrednosti takoj zapisali v x, ni treba razbiti vsote na dva dela)
for k in range(3):
xk_1 = x.copy()
print(5*'-' + f'iteracja {k}' + 5*'-')
for i in range(len(A)): #opazujte kaj se dogaja, ko to celico poženete večkrat!
x[i] = (b[i]-K[i,:].dot(x))/A[i,i]
print(f'Približek za element {i}', x)
e = np.linalg.norm(x-xk_1)
print(f'Norma {e}')
Preverimo rešitev
A@x
Metoda deluje dobro, če je matrika diagonalno dominantna (obstajajo pa metode, ki delujejo tudi, ko matrika ni diagonalno dominantna, glejte npr.: J. Petrišič, Reševanje enačb, 1996, str 149: Metoda konjugiranih gradientov).
Nekaj vprašanj za razmislek!¶
Na sliki je prikazano paličje. Ob delovanju sil $F_1$ in $F_2$ se v palicah razvijejo notranje sile $P_i$. Dimenzije paličja zagotavljata kota $\alpha$ in $\beta$.
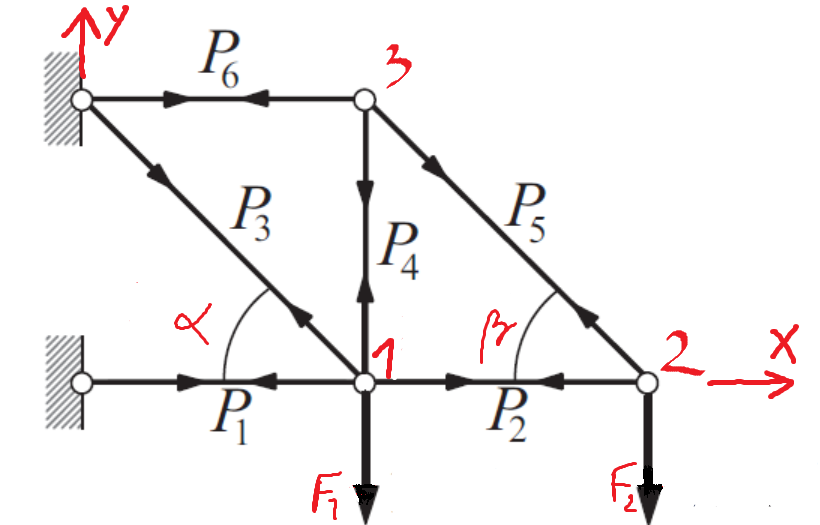 Sile v palicah izračunamo s pomočjo sistema linearnih enačb.
Sile v palicah izračunamo s pomočjo sistema linearnih enačb.
- V simbolni obliki zapišite ravnotežje sil za točko 1 v $x$ in $y$ smeri (namig: naloga je posplošitev naloge 15 na strani 81 v knjigi Numerical methods in Eng with Py 3 z nastavkom za rešitev):
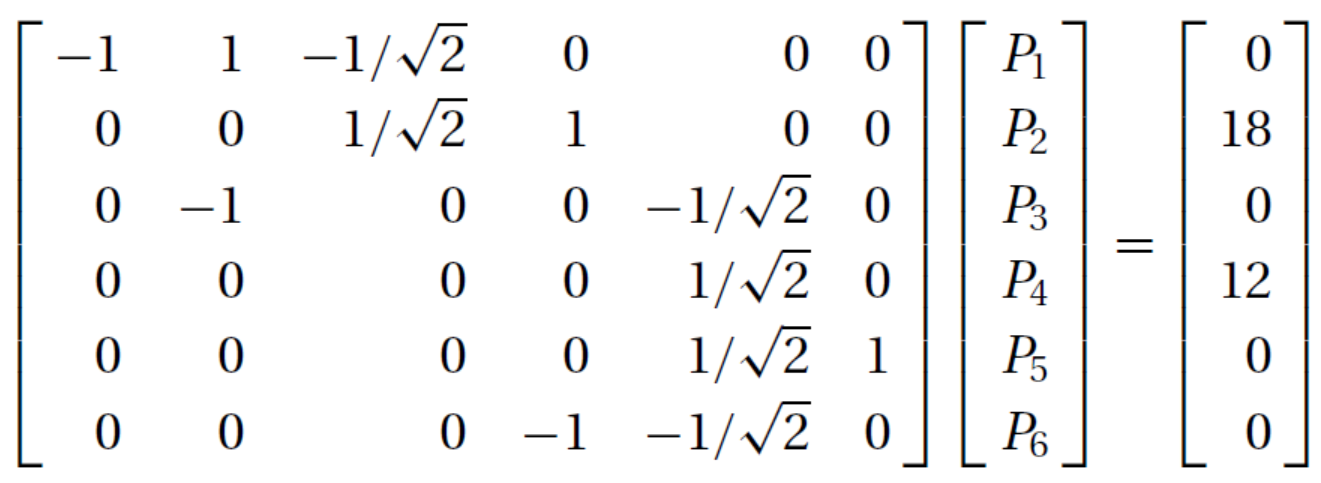 Zgornji nastavek ima napako v predzadnji vrstici. Rešitev sistema v knjigi je: $P_{1} = -42000, P_{2}=-12000, P_{3}= 42426, P_{4} = -12000, P_{5} = 16971, P_{6} = 12000$
).
Zgornji nastavek ima napako v predzadnji vrstici. Rešitev sistema v knjigi je: $P_{1} = -42000, P_{2}=-12000, P_{3}= 42426, P_{4} = -12000, P_{5} = 16971, P_{6} = 12000$
). - V simbolni obliki zapišite ravnotežje sil za točko 2 v $x$ in $y$ smeri.
- Najdite simbolno rešitev za sile $P_i$.
- Uporabite podatke: $\alpha=\beta=\pi/4$, $F_1=18$ kN in $F_2=12$ kN ter najdite številčno rešitev.
- Pripravite si funkcijo, ki bo za poljubne podatke (npr:
podatki = {a: pi/4, b: pi/4, F1: 18000, F2: 12000}) vrnila numerično matriko koeficientov $\mathbf{A}$ in vektor konstant $\mathbf{b}$. Če ne uspete tega narediti avtomatizirano, delajte "na roke" (splača se vam potruditi, saj bomo to večkrat rabili). - Razširite zgornjo funkcijo, da vam vrne rešitev linearnega sistema (uporabite kar
numpyknjižnico) - Predpostavite $F_1=F_2=10$ kN. V vsaj petih vrednostih kota $\alpha=\beta$ od 10$^{\circ}$ do 80$^{\circ}$ izračunajte sile v palicah.
- Za primer iz predhodne naloge narišite sile v palicah.
- S pomočjo funkcije
np.linalg.solveizračunajte inverz poljubne matrikeA(nato izračunajte še inverz s pomočjo funkcijenp.linalg.inv). - Na primeru poljubnih podatkov (npr:
podatki = {a: pi/4, b: pi/4, F1: 18000, F2: 12000}) pokažite Gaussovo eliminacijo z delnim pivotiranjem. - Na primeru poljubnih podatkov (npr:
podatki = {a: pi/4, b: pi/4, F1: 18000, F2: 12000}) pokažite Gauss-Seidlov iterativni pristop k iskanju rešitve.
Dodatno¶
Analizirajte, koliko e-mailov dobite na dan:
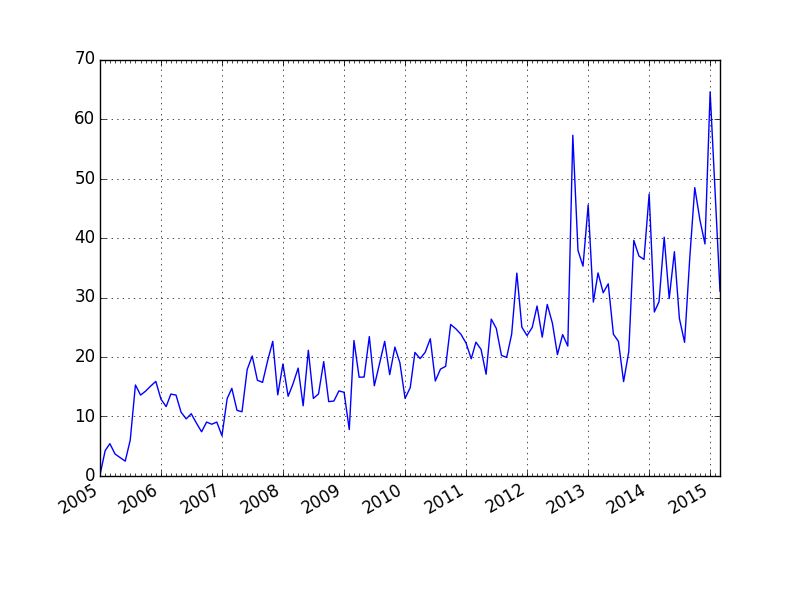 https://plot.ly/ipython-notebooks/graph-gmail-inbox-data/
(Nasvet: sledite kodi in uporabite
https://plot.ly/ipython-notebooks/graph-gmail-inbox-data/
(Nasvet: sledite kodi in uporabite matplotlib za prikaz).